
2 月16 日,OpenAI 发布最新文生视频大模型 Sora ,并在官网发布由其生成的 48 个视频样例。 目前,Sora 仍处于测试阶段,仅对部分评估人员、视觉艺术家、设计书和电影制作人开放访问权限。
Sora 在视频生成和模拟能力实现重大突破。基于通用视觉数据的模型 Sora 具有强大的功能,具体来看:
1)视频生成和处理能力:生成长达 1 分钟的视频,远超此前 Pika 的 7 秒、Runaway Gen2 的 18 秒,视频画面的表现和构图效果更佳。并且,生成视频具有3D 一致性,即可生成具有动态摄像机运动的视频,随着摄像机的移动和旋转,人物和场景元素在 3D 空间中保持一致移动。

2)图像生成能力:生成不同大小、分辨率最高可达 2048x2048 像素的图片。3)模拟能力:在 3D 空间中模拟人类、动物、 自然环境的特征,生成视频符合物理世界的规则。并且还能模拟数字世界、生成程序游戏。
【不仅是多模态,Sora 为世界模型的实现奠定基础】
此次文生视频模型 Sora 的发布是 OpenAI 继文字、图像之后,在内容生成领域的又一突破。同时,其强大的视频生成和模拟能力标志着 AI 技术在多模态领域实现重大突破。该模型强大的功能有望进一步优化内容创作者的视频制作流程,促进优质内容生产。并且,模型所具备的模拟物理世界和数字世界的能力或将加快世界模型的实现进程,推动游戏开发、虚拟现实等领域的发展。
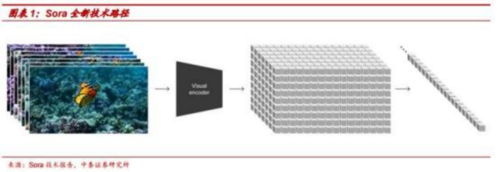
Sora 采用 Transformer 架构,并用 patches 作为训练和预测的基本单位。1)数据处理:类比于大语言模型将各种文本统一为 tokens, Sora 将不同的视频和图片等视觉数据压缩在低维潜空间中,将其分解为统一的 patches,以此作为视频大模型训练和预测的基本单位。2) 计算架构 :Sora 采用的是 duffis ion transformer 架构 , 即基于 transformer 编码器-解码器的架构,对经过增加噪点处理的 patches 进行编码,再通过解码器逐步还原出原始 patches 的预测。随着训练数据的增加,样本质量将显著提升。














